








Advances in artificial intelligence and machine learning are often perceived as a threat to the creative process. But at Foster + Partners, the Applied Research and Development group is rethinking this mindset and embracing machine learning, not to replicate or replace designers, but to enhance our knowledge, instincts and sensitivities, free us from routine tasks, and to optimise and push the boundaries of our designs.
29th March 2021
Towards Artificial Intelligence in Architecture: How machine learning can change the way we approach design
Architecture today is a multi-skilled profession, calling on disciplines from structural and environmental engineering, to social and material sciences. At Foster + Partners, we have a long history of exploring, adapting and harnessing available technologies in order to expand and improve our design capabilities. At the forefront of this is the Applied Research and Development (ARD) team, who have recently been investigating the potential of using artificial intelligence (AI) in the creative process.
As a field of academic study, AI was established in the 1950s and can be broadly defined as the development of machines that display human intelligence and behaviours. Since its genesis, it has been a fertile topic of debate, repeatedly making headlines – both good and bad – and becoming enshrined in popular culture and science fiction. Thankfully, AI has continued its evolution with mostly altruistic innovations: it can help us to understand and react to human speech, screen for breast cancer, develop robots and self-driving cars, or just recommend us films we’d like to watch.
The cutting-edge area of ARD’s research investigates the potential for these systems to provide genuine design assistance.
There are many systems and processes that need to be perfected in order to accurately mimic human intelligence; an example would be the subset of AI known as machine learning, summarised by computer scientist Tom Mitchell as ‘the study of computer algorithms that allow computer programs to automatically improve through experience.’
Slide 1 of 1

English mathematician and pioneer of computer science, Alan Turing, standing at the Ferranti Mark 1 computer at the University of Manchester in 1951. The earliest successful AI program was written by Christopher Strachey to play checkers, or draughts, and ran on the Ferranti Mark I. Courtesy of Science & Society Picture Library / Getty Images
In the context of architecture and design, machine learning has great potential to analyse our designs more quickly and at less cost. The ARD team have been exploring two ways in which it can be incorporated into the design process, as well as some potentially more revolutionary applications.
The first is known as surrogate modelling; a direct replacement for analytical engineering simulations (such as structural deformation, solar radiation, pedestrian movement), which take valuable hours, or even days to complete.
There is an enormous scale and complexity to many architectural projects today, typified by a varied array of intersecting expertise and technologies. To assist in this diversified field, machine learning might enable us to solve problems and detect patterns historically dependent on the complex analytical simulations and programmes. Design optimisation based on their findings has been nearly impossible due to the time and work involved, undermining the benefit these tools can provide.
Slide 1 of 1

Demonstrating the complexity of the cutting-edge nature of the architecture profession, the staff at Foster + Partners are specialised in an extraordinary range of disciplines. Covering over 200 different qualifications, our staff include aerospace engineers, computer scientists, game artists, sociologists, geologists and fine artists. © Nigel Young / Foster + Partners
To solve this problem, we need to provide designers with results in near real-time. For that reason, the ARD team investigated surrogate models, where a computationally ‘cheaper’ predictive model is constructed based on a number of intelligently chosen simulation results. The designer can then have results from the surrogate model’s approximation of a simulation in real-time, which is good enough for them to make a quick decision.
The second – and more cutting-edge – area of ARD’s machine learning research we call ‘design assistance’ modelling, and the potential is for these systems is to work alongside the intuition of designers in the creative process.
We call this design-assistance modelling because it helps facilitate architectural processes for which we do not necessarily have an analytical answer – one that can be derived from simulations. This could be, for instance, the optimal spatial layout of furniture within a space or providing designers with document control assistance in real-time while they are working.
Machine learning: artificial neural networks
As with most scientific endeavours, there are many approaches to the task of programming a machine to learn. One gaining a lot of traction is the use of artificial neural networks. These networks are loosely based on the neurons and synapses in our brain and how they interact. They contain millions to billions of artificial neurons that perform and develop – in very broad strokes – like the human mind does: taking data as an input, processing it through the network of neurons and outputting a response. The processing of data at the beginning is not useful, and the outcomes are far from desirable, but, through a process of feedback, a learning cycle is established, and improvements begin.
Slide 1 of 1
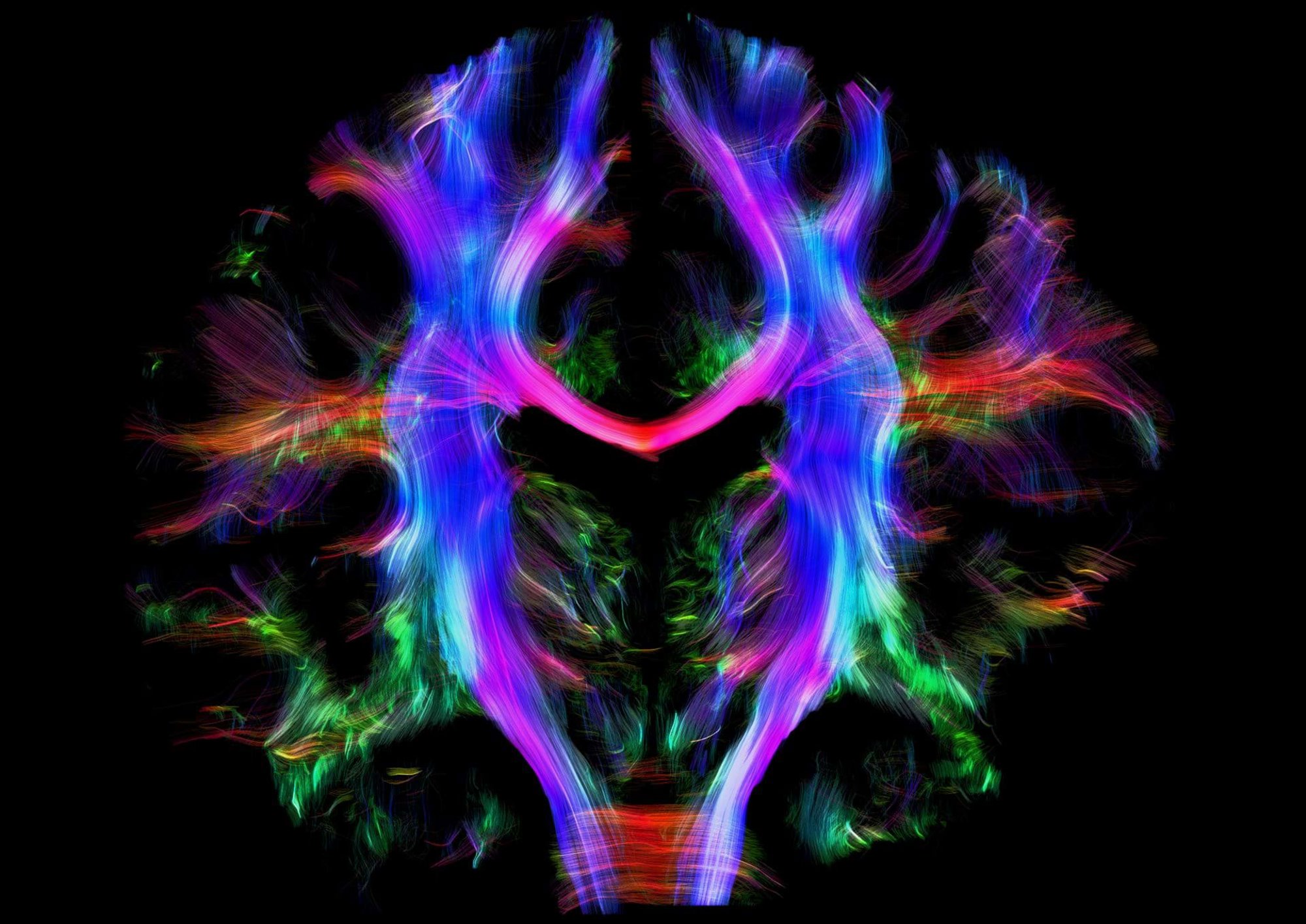
Pathways of nerve fibres – long, slender projections of nerve cells, also known as neurons – connecting in the brain of a young adult. This tractography image was created using a type of magnetic resonance imaging (MRI) at the Max Planck Institute for Human Cognitive and Brain Sciences. © Alfred Awander. CC-BY
Imagine, for example, a child learning to balance a pen on its finger, getting a feel for how the weight of the pen is distributed as they try to balance it. Unremarkably, at the beginning, it will fall – a lot – but every time the pen falls, the child gets closer to identifying the ideal balancing point.
However, when the child is presented with a new pen, with a different shape, the exact rules established for the previous pen will likely no longer apply. So, in order to learn how to balance any pen (and become an expert ‘pen-balancer’), the logical next step is to set about trying with hundreds, if not thousands, more. The resulting expertise allows a person to infer – subconsciously analysing factors like shape, profile and cross-section – how the weight of a new pen is distributed and its ideal balancing point. The quality of our guesses will be highly dependent on the amount and quality of our data and training. In the case of our child example, this sort of training occurs naturally over the course of childhood, as we pick up and interact with all sorts of objects. Appropriately, in machine-learning terms, this is called the ‘training’ phase.
Now imagine that we want a robot to do the same task for us. We would need to collect data about different pens – their length, cross-section and weight distribution – and then test for the optimal balancing point. We would go on to write a procedure that gives explicit conditional instructions to the robot, manually encoding the knowledge about the pens we surveyed. The program would be long but, at the end, given a pen from those we collected, our robot can potentially balance it on its finger.
But what happens if we want to use a pen from outside our original survey, or maybe a paint brush? Since we have had to explicitly define the balancing point (output) for every possible pen in our survey (input), we would have to rewrite or expand the code for every new object. This is not always possible, and certainly isn’t efficient.
An artificial neural network avoids this situation by going through its own training phase – the learning process of trial and error. Once trained, the robot should be able to perform the task on its own, without us having to give explicit and exhaustive instructions. Not only that, but if the training is successful, the network will even generalise, and the robot will be able to balance any object with properties similar to those of a pen. It will have learnt to infer – like the child – how to do so; this is called the ‘inference’ phase.
Machine learning in architecture
Within architecture, there are numerous tasks for which artificial neural networks could prove useful. At the most basic level, this could be the classification of a design based on its typology.
Let’s say that we wanted to recognise and classify Palladian villas from a pool of images. Using machine learning we could quickly identify whether each image satisfied all criteria for that building typology. To do this, we would feed the network thousands of images of villas, telling it which of these represent Palladian architecture. After training itself on this data, the system can ‘infer’ with high accuracy whether any image of a building presented to it is an authentic Palladian-style design.
What makes machine learning particularly effective in this case is that we have not explicitly defined what the characteristics of a Palladian villa are; the system, during its training, identifies these traits autonomously.
Slide 1 of 1

Italian architect Andrea Palladio’s Renaissance Villa la Rotonda, completed after his death in 1580, sat atop a hill outside Vicenza in northern Italy. Palladio’s designs are recognisably inspired by Roman architecture but uniquely distinguishable due to his choice of classical architectural elements and assembly of them in innovative ways. © Zairon CC BY-SA 4.0
However, despite its noticeable benefits, the Palladian villa example can only go so far in demonstrating the potential for machine learning to assist in the creative process. What makes machine learning interesting is its potential to effectively respond to a ‘creative’ question, one to which there is not an objectively correct response. The Palladian villa typology – based as it is on a finite number of built examples – can be defined through a description of its fixed architectural rules. We were asking the system a question to which we could already find an accurate answer (admittedly at a cost in terms of time and labour).
What if we wanted our system to capture the more subjective, elusive or unpredictable qualities of architecture? We can know what the defining characteristics of a Palladian villa are, but can we universally pinpoint all the characteristics of a successful public plaza, for example? If we train a machine learning system with a set of thousands of public spaces and point out the successful ones (it is much easier to identify an already successful public space than it is to comprehensively define what it is that makes it so), that system could then be tasked with generating other spaces that have similar traits.
Architectural datasets are rich, complex and often produced in great numbers. They can provide huge amounts of invaluable information and are ideally suited to train AI systems.
In many cases, this training process comes up with invaluable results: the new spaces would be embedded with characteristics and correlations that may be too obscure or complicated for the user to infer, formulate and encode independently. It is worth pointing out that one of the downsides of these systems is that we cannot interrogate the machine about said characteristics, despite the fact that they are usually incorporated, we can only review its results.
Data: original versus synthesised
With machine learning, the input data is the key: the success of the system’s output is only as good as the volume and quality of data we can provide. In our public space example, it is evident that the more examples of good public space we provide, the more useful the results will be.
Fortunately, architectural datasets are rich, complex and often produced in great numbers; they can provide huge amounts of invaluable information and are ideally suited to train AI systems.
Slide 1 of 1

The Foster + Partners archive holds all of the studio’s many thousands of precious drawings, models, slides and photographs, publications, awards and other practice-related ephemera. Our digitized image server alone contains over 600,000 files – an indication of the scale of the data challenge facing the ARD team. © Nigel Young / Foster + Partners
Data is a necessity in both surrogate and design assistance models. Generally, there are two types of data we can work with: original or synthesized. At Foster + Partners, original data exists as our archive of drawings, models, sketches, details and so on, produced over the practice’s more than five decades of existence. Synthesized data, on the other hand, is automatically generated with the help of a generative design system. Examples of such datasets that we’ve used during our research are discussed further below.
Currently, each data type presents its own challenges. For original data, for example, it can be time consuming to sift through decades of digitally archived work in different file formats, produced by thousands of employees, for thousands of different projects, to identify the data that would be applicable to our task. While synthesized data may not always be an option either, as creating generative models with the richness of information required may prove an almost impossible task.
Self-deforming facades: simulation of thermo-active laminates
In 2017, the ARD team collaborated with software company Autodesk on a research project inspired by recent advances in material science. Smart, passively actuated materials – materials that can change their shape without any help from external mechanical forces – react like living organisms, adapting to changes in their physical environment such as temperature, light or even humidity. The team believe that, in the future, they could have great architectural potential.
An adaptive, passively actuated facade, for example, might not have any mechanical shading devices, such as motor-controlled louvres, but rather would self-deform under external light conditions – like an eye’s dilating iris – to provide shading, prevent overheating or increase privacy.
This could be achieved by mixing patterns of thermo-active materials around passive laminates (multi-layered materials), where a difference in expansion and contraction rates occurs. That difference, if curated, can lead to specified deformations, which architects and designers could control and exploit.

The team was interested in the material’s morphological deformation: a controlled transition from an initial state to an end state and back. However, there is a non-linear relationship between the laminates’ internal forces and their displacements. This is opposed to a more common linear analysis, where the effect of tweaking input parameters on the output is predictable. For example, a cantilevered beam of known dimensions and material will always deform in the same way under a particular constant force. But it will deform in a non-linear way during an earthquake. As a result, non-linear analysis requires a sophisticated and time-consuming simulation strategy.
In our research every laminate had an initial, non-deformed state (a ‘fully open’ façade in the adaptive shading example) and a target deformation (a ‘fully closed’ façade). However, faced with a non-linear problem, it is difficult to predict how different parameters – such as the pattern of the thermo-active material over the laminates – would affect the resulting deformation under a given temperature.
An adaptive, passively actuated facade … would self-deform under external light conditions – like an eye’s dilating iris – to provide shading, prevent overheating or increase privacy
One way to approach this problem would be to repeatedly change the laminate’s layering and analyse the results, hoping that the changes would steadily yield results closer to the target deformation. However, given the complexity of the non-linear simulation, this process of trial and error would be extremely time consuming. So, we decided to use machine learning to build a surrogate model.
Before the system could begin its ‘training’, Foster + Partners and Autodesk had to produce enough synthesised data from which it could learn. We developed a parametric model that generated hundreds of laminates and simulated their deformation. This process was run in parallel and distributed (using our in-house custom-written software called Hydra, which builds and analyses the data tens-of-times faster than commercial modelling software) on our computer cluster. Subsequently, we took this dataset (the deformations derived from the initial states) and fed it into two artificial neural networks competing against each other.
Slide 1 of 1

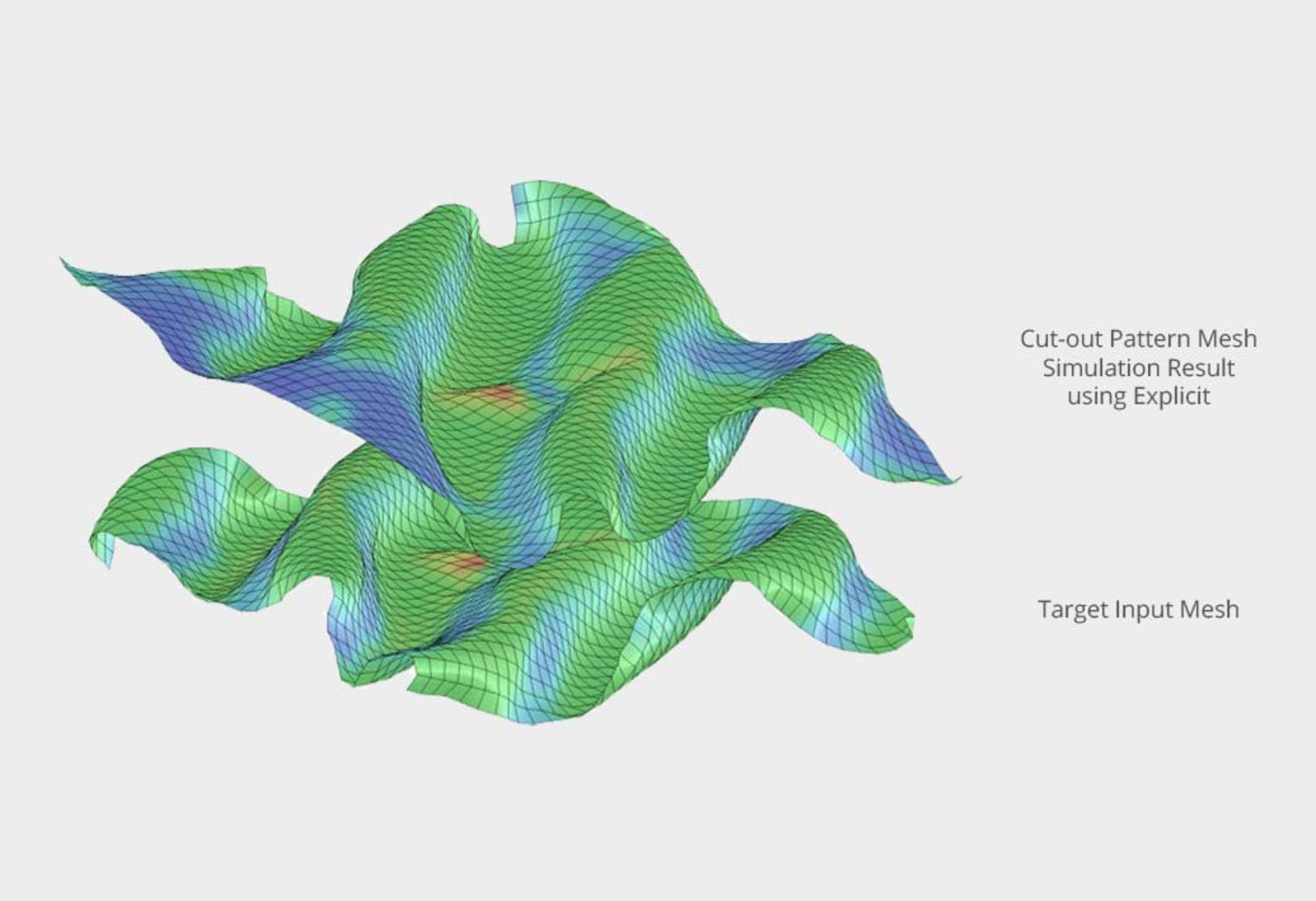
The left pair of images shows a laminate in its initial state (above) that is then encoded into a grey-scale image (below). The right pair shows the same laminate in the deformed state (after running a non-linear structural analysis) and its encoding to a depth map. The different colours show how much each part of the laminate was deformed. © Foster + Partners / Autodesk
Slide 1 of 1

These images show how the system learnt to predict the correct material layering pattern that would produce each desired depth map (or material in its deformed state). The left column shows the required depth maps that were presented to the system and the far-right column is the target layering required. In-between we see the system progressing towards the target. © Foster + Partners / Autodesk
In this instance, rather than providing a single neural network with data, such as pens, and it training to balance them, we are asking two networks to learn from and improve each other. In our example, one network would be a teacher – a ‘pen balancer’ – that has data on both pens and balancing points, and it ‘trains’ the other network to design new pens that balance from a specific point of its choosing. As the latter network’s training progresses, it gets better at creating pens that can balance wherever it intends. At the same time, the teacher-network is also improving and getting a better understanding of the physics behind how pens balance. This process is called adversarial learning and, ultimately, the pair reach an equilibrium where both networks cannot improve anymore.
[Our] workflow not only completely challenges the way these laminates are designed, it also suggests a methodology that reduces the material’s costly and time-consuming prototyping phase
In our research, we trained this system – known as a generative adversarial network (GAN) – on deformed laminates (the ‘inputs’) and the pattern of these laminates required to cause a particular deformation (the ‘outputs’). After its training, the machine learning system was then able to create accurate laminate layering for a known deformation result within milliseconds.
Slide 1 of 1
A comparison between an arbitrarily designed laminate in a set deformed state (below) and the result of an original non-linear analysis run on the laminate’s initial state (above), as predicted from the set deformation. Those two deformations are not identical but close enough to prove the effectiveness of this approach and system’s ability to generalise. © Foster + Partners / Autodesk
The result allowed the research team to prototype a simple yet novel application where a designer could design a laminate in a target deformed state – such as a fully shaded facade – and be presented with the necessary cut-out patterns that would produce this result.
This has resolved the inversed problem with which we started: instead of a designer repeatedly adjusting the laminates to produce an acceptable deformed state, the system allows the designer to conceive the output deformed state first, and then be presented with the required material pattern. We are effectively using the initial surrogate machine learning model as a design-assist one.
Slide 1 of 1
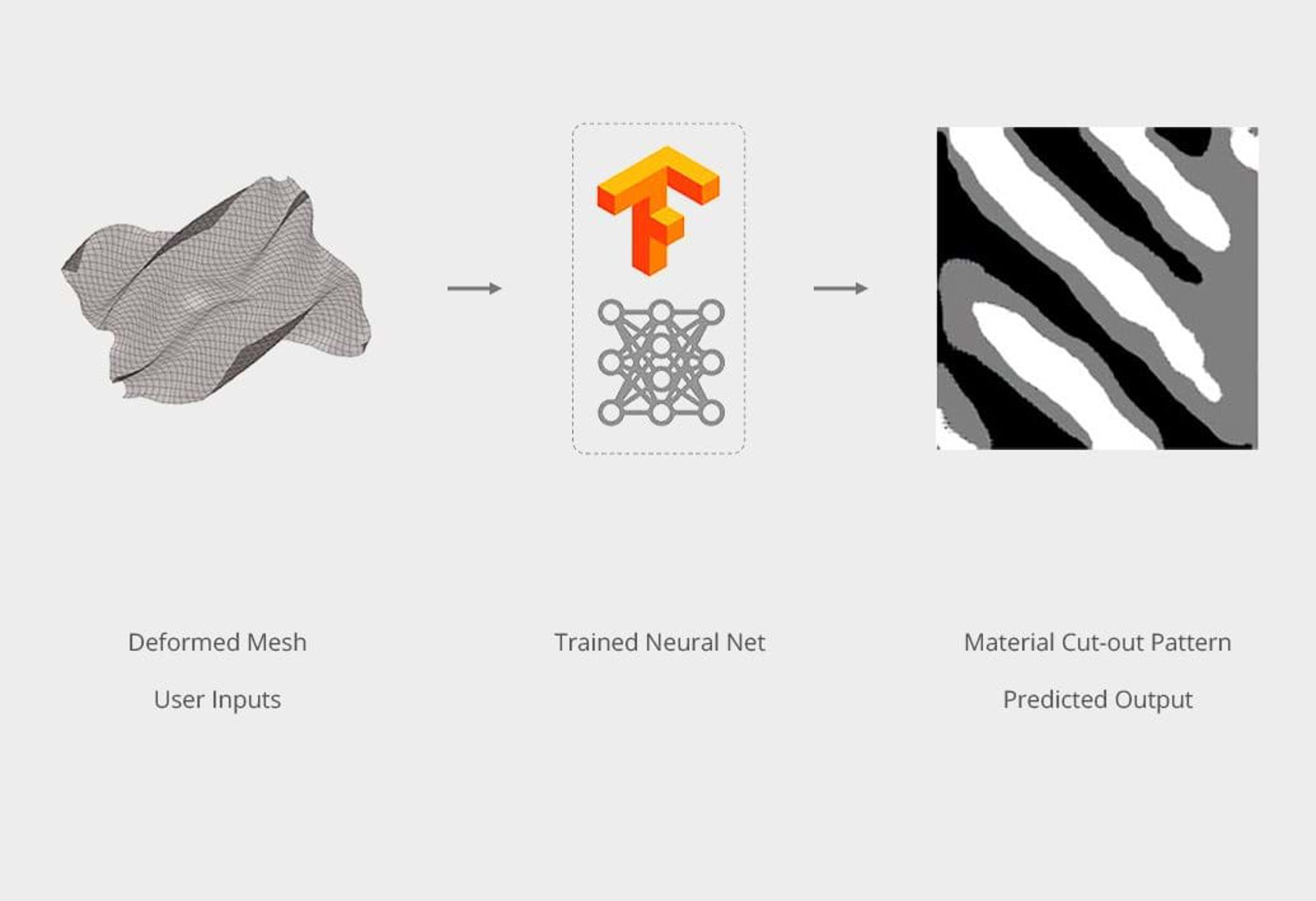
A material with a desired deformed state (left) is inputted into the trained neural network (centre) and the required material cut-out pattern is provided by the system (right). This is the reverse of how the problem was initially conceived, where the diagram shows how an inverse problem is solved after the training has finished. © Foster + Partners / Autodesk
This workflow not only completely challenges the way these laminates are designed, it also suggests a methodology that reduces the material’s costly and time-consuming prototyping phase, opening up the potential for its practical inclusion within an architects’ advanced and sustainable material swatch book.
Real-time floor plan analysis: spatial and visual connectivity
Spatial and visual connectivity (or visual graph analysis) are two of the various metrics we use to evaluate the performance of a floor plan. In an office, for example, they are useful for helping understand how well a floorplate works in terms of visual navigation, walkability, the balance of private offices and shared spaces, and the encouragement of serendipitous collaboration. However, the two analyses can take a long time to compute for large-scale floor plans.
The ARD team wanted to significantly cut down this workflow to a near real-time experience, to make the analysis accessible and intuitive for designers during – rather than after – their design process.
Previously, we used state-of-the-art algorithms and parallelisation techniques to get the analysis down to minutes, but this was not anywhere near real-time performance. So, we investigated the use of machine learning and training a surrogate model to mimic the analysis output.
Similar to the laminate research, the team developed a parametric model capable of generating basic office floor plans that incorporate open-plan and compartmentalized workspaces, complete with walls, doors and furniture. This generative parametric model created a synthetic dataset of thousands of floor plans. Then, using Hydra, we ran spatial and visual analyses on those synthetic plans.
The result was a set of thousands of random floor plans (our inputs), each with a corresponding set of visual and spatial analysis results (the outputs). This data could then be used to train the machine learning system to provide us with spatial and visual connectivity analysis of any given floor plan, without the need to run a simulation.
Slide 1 of 1

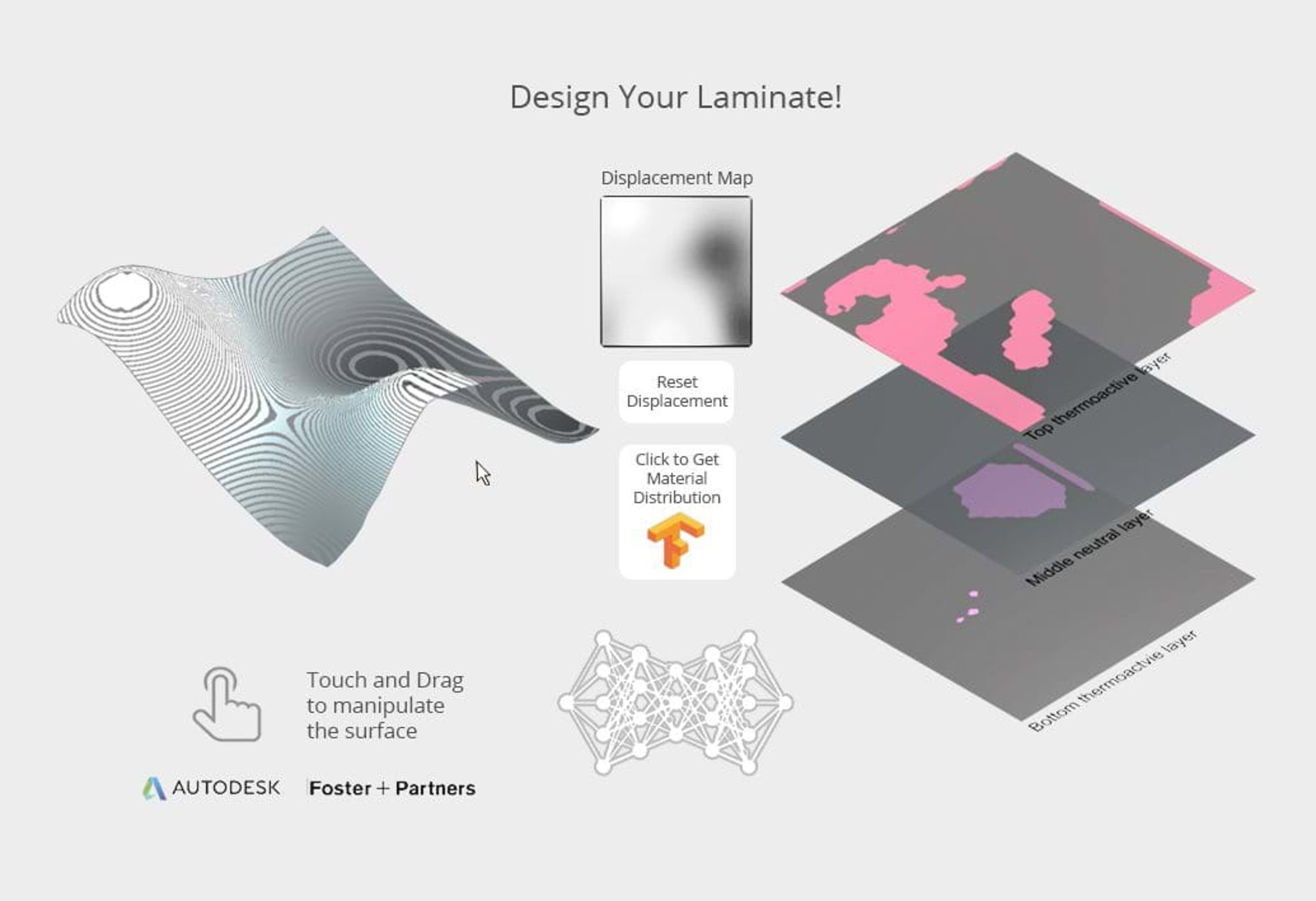
The top row of images shows a sample of floor-plan outputs from the parametric model, showing three compartmentalized (left) and three open-plan work spaces (right). The middle row visualises the output of the spatial connectivity analysis on these floor plans, and bottom row shows the visual connectivity analysis. © Foster + Partners
As part of the system’s ‘training’, it is continuously trying to improve itself, comparing the results it creates against those it was provided with. Its results at the beginning are horribly inaccurate. But, as time goes by, and as the artificial neural network learns from feedback, it starts to correct its mistakes and its answers get closer to being correct. By the end, the model finds its own ‘recipe’ to map from input (a floor plan) to output (a floor plan with the correct spatial and visual connectivity analysis) – and it’s not a recipe that we provided. The system can then analyse new floor plans based on its completed analysis of thousands of examples, training itself over and over again through trial and error.
Slide 1 of 1
A series of stills showing the model’s floor plan analysis. In each frame, the left-hand floor plan shows correct (and pre-known) output of connectivity analysis on that plan. While the central animation (showing the same floor plan) is the model’s steadily improving predictions of this analysis as it trains. By the end of the animation (bottom right), it matches the correct analysis shown in the left-hand plan. The right-hand plan illustrates the difference between the two, darkening as the model’s prediction gets closer to reality. © Foster + Partners
Once the machine learning model has completed its training, it can be put to work running both spatial and visual analyses on any of an architect’s floor plans, producing results in less than 0.03 seconds. Equipped with such a powerful tool, the designer can now see the effectiveness of a change in office arrangement on screen as they make the adjustment.
Design assistance models: looking to the future
The ARD group’s most current research is mainly targeted towards design assistance models. The team is exploring the benefits that machine learning can offer to architects instantaneously, as they design. For that, we are trying to identify interesting design problems, without analytical solutions, for which we have enough original data to train our system.
One such problem is the layout of furniture. While, as we have seen, the office floor plan can be analysed and evaluated based on its visual and spatial connectivity results, a given furniture configuration for a residential or office building is – like the example of analysing successful public spaces – more subjective; it does not have a set of formal and objective conditions on which it can be judged.
So, how can we train a machine learning system to know what a desirable or even optimal residential furniture layout could be? This requires the system to imitate not only the technical knowledge and experience of a designer but also their intuition.
Approaching this task as a machine learning initiative first requires an original dataset; thousands of ‘good’ furniture layouts that could help train our system. Exactly how that data is gathered, standardised, tagged and augmented is a complex challenge the team is currently engaged in. Building this machine learning pipeline will eventually allow the system to make suggestions for potential layouts in real-time, given an initial floorplate configuration.
This is just one example of many design assistance models that the ARD team is working on. The driving objective is not to replicate or replace designers but to harness the power of machine learning to assist with the creative process, to enhance our knowledge, instincts and sensitivities, to free us from routine tasks, and to help us develop our intuition about correlations that are not immediately obvious or measurable. New technologies, when treated not as a threat but as a possibility, enable us to explore new ideas, to enhance creativity, and to constantly optimise and push the boundaries of our designs.
Autodesk Collaborators:
Panagiotis Michalatos
Amira Abdel-Rahman

Author
Martha Tsigkari, Sherif Tarabishy, Marcin Kosicki | +Plus Journal
Author Bio
Architects Martha Tsigkari, Sherif Tarabishy and Marcin Kosicki are members of the Applied Research and Development group at Foster + Partners, a team that provides expertise in computational design, performance analysis, optimisation, fabrication and interaction design.
Editors
Tom Wright and Hiba Alobaydi